

 by
by Vývojáři Googlu publikovali způsob, jak vytvářet, rozšiřovat a zdokonalovat překladový slovník mezi libovolnými dvěma jazyky:
Počítač se na obrovském množství jednojazyčných textů každého z obou jazyků učí jejich jazykovou strukturu: studuje u každého jednotlivého slova nejen jeho frekvenci výskytu, ale např. i slova, která nejčastěji stojí před a za ním – tak je možné statisticky stanovit pravděpodobnost sledu určitých lexikálních jednotek po sobě.
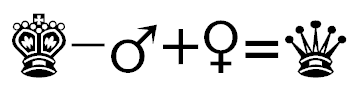
Symbolicky vyjádřený příklad analogické relace v různých jazycích
Na základě analýzy struktury se definuje celý jazyk jako systém mezi sebou propojených slov, který vytváří matematický model.
Vzhledem k tomu, že jsou si současné jazyky strukturálně podobné – odráží totiž strukturu stejného světa –, je tak možné tento matematický model – slovní zásobu jednoho jazyka – pomocí srovnání známých dvoujazyčných překladů analogicky promítnout do druhého jazyka a odvodit překlad výrazů zatím neobsažených v překladovém slovníku.
Nová technologie se zavádí do systémů strojového překladu jako je Google Translate a má tak přispět k jejich dalšímu zdokonalení.
Tomas Mikolov, Quoc V. Le, Ilya Sutskeve: Exploiting Similarities among Languages for Machine Translation
Obrázek: © Radim Sochorek

