by
by Kdo dnes používá moderní software k strojovému překladu textů, využívá většinou nevědomky vynálezu německého informatika Philippa Koehna. Svou inovativní metodu „Statistical Phrase-Based Translation“ (překlad založený na statistice vět) popsal poprvé před deseti lety v jednom sborníku.
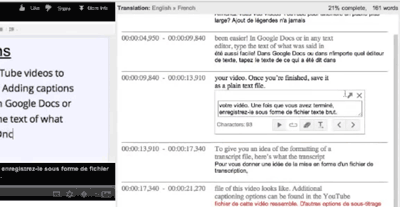
Zatímco do té doby dokázal software překládat věty prakticky jen slovo po slově se zohledněním naučených gramatických pravidel, Koehnův model je založen na statistice:
Na základě vyhodnocení dokumentů v různých jazycích se počítače učí v textech automaticky rozpoznávat segmenty vět a jejich odpovídající překlad v druhém jazyce. Počítače na základě těchto poznatků a pravidel slovosledu analyzují text k překladu a navrhují nejpravděpodobnější – ve velkém množství textů v příslušném kontextu nejčastěji se vyskytující – překladové varianty jednotlivých segmentů. Posledním krokem je smysluplné poskládání segmentů do gramaticky správně utvořené věty v cílovém jazyce.
Z logiky věci vyplývá, že největší výzvou je výběr správných kombinací segmentů: Pokud existuje ve větě s 30 slovy pro každé 2. až 5. slovo řada variant, dostaneme se snadno na několik miliónů variant překladu této věty.
Tento postup je možné shrnout do dílčích částí „jazykový model – trénink – dekódování“. Na něm jsou založeny v podstatě všechny současné algoritmy strojového překladu na trhu.
Pro trénování Koehnova systému první generace se používaly lidskými překladateli přeložené stenografické protokoly plenárních zasedání Evropského parlamentu z období 1996–2012.
Koehn nabízí vlastní systém strojového překladu jako open source software na platformě Moses. Tu využívá i Evropský parlament od té doby, co pozastavil překládání stenografických protokolů.